Although a fan of the official Azure SDK for Go, I’ve found myself writing more and more smaller utils simply against the Azure REST APIs. Maybe it’s just me trying to get to grips with the SDK (I use it for a few weeks then leave it for months, then back again…. so it’s never fresh in my mind). But I always find myself going back to REST.
Whenever I go back to REST I also go through the usual dance (although fairly quick) of how do I authenticate, what’s the endpoints again etc etc. This time I want to document what I’m currently doing (as of end 2019) and maybe it will help myself (and others) in the future.
Firstly, let’s authenticate and see about an operation or two against Azure.
Prerequisites
Firstly, I’m assuming that you’ve already made a Service Principal (SP) to use against your specific Azure resource (see here ). Once you’ve got a SP you’ll have 4 pieces of information you’ll need for authentication:
- Client ID
- Client Secret
- Tenant ID
- Subscription ID
Once you have those 4 pieces of info, you’re good to go.
Authentication
All Azure REST calls require the Authorization header to be set in the HTTP request. To generate the correct token to insert, you simply need to generate an OAuth2 request to the Microsoft login URL.
urlTemplate := "https://login.microsoftonline.com/%s/oauth2/token"
bodyTemplate := "grant_type=client_credentials&resource=https://management.core.windows.net/&client_id=%s&client_secret=%s"
url := fmt.Sprintf(urlTemplate, tenantID)
body := fmt.Sprintf(bodyTemplate, clientID, clientSecret)
request, _:= http.NewRequest("POST", url, strings.NewReader(body)
The above is the basics of generating a token that can then be used for all subsequent calls. The response from the POST will return 2 key pieces of information, one is the actual token string itself and the other is the expiry of the token. This way we can use the same token for a certain duration without having to go through token generation again and again.
Once we have the token, we simply create a header “Authorization : Bearer ”
Before going any further, it would be remiss of me not to mention the UTTERLY BRILLIANT site of https://docs.microsoft.com/en-us/rest/api/appservice/ . This is basically the Azure REST API documentation site, but most importantly it allows you try literally try the API out (using your own acct). Being able to see the HTTP requests (headers, body etc etc) and see the responses come in is invaluable.
For example, for list app settings in an app service:
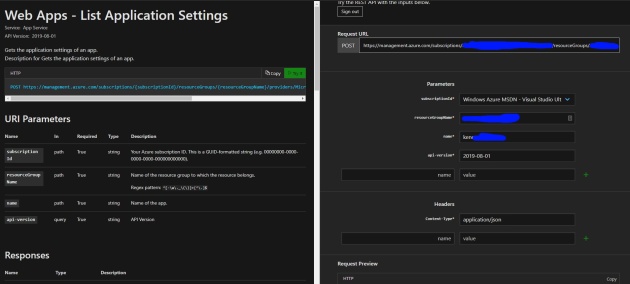
generates the request
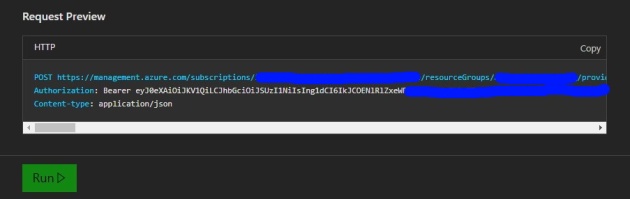
which produces the results
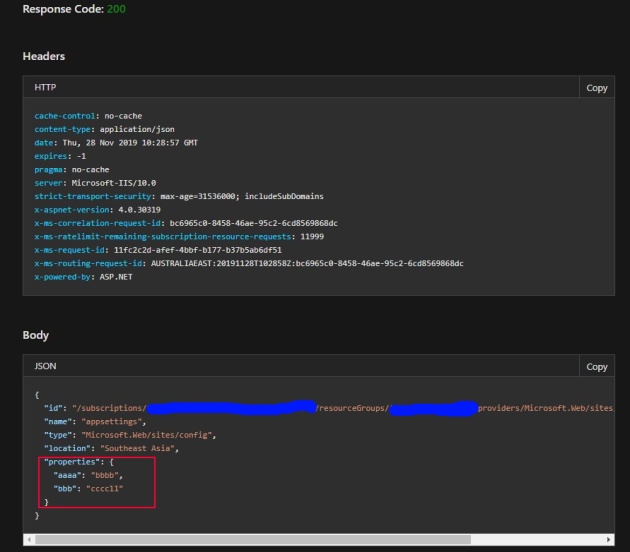
Now, I won’t go through the unmarshalling etc that’s required (but trust me,JSON to Go is your friend) but you get the idea. In this case we have 2 appsettings key/value pairs set, highlighted in red.
So, now we know what the query should look like and the response we should get, let’s code it. Firstly the query.
template := "https://management.azure.com/subscriptions/%s/resourceGroups/%s/providers/Microsoft.Web/sites/%s/config/appsettings/list?api-version=2019-08-01"
url := fmt.Sprintf(template, subscriptionID, resourceGroup, appServerName)
req, _ := http.NewRequest("POST", url, nil)
req.Header.Set("Content-Type", "application/json")
client := http.Client{}
req.Header.Set("Authorization", "Bearer "+accessToken)
resp, _ := client.Do(req)
Note, yes I find it a bit weird that to retrieve (ie GET) the app settings we need to do a HTTP POST, go figure ![]()
Anyways, if we’ve got our subscription, resource groups etc etc then generating the query required is very basic. Once again we’ll just get back the raw JSON and unmarshal back to a suitable struct.
The most important thing I think you need to remember is go to the documentation pageand use the “Try it” button. Seeing the request/responses against your own services makes everything so much easier before you write a single line of code!











